http://www.fravia.org |
|
|

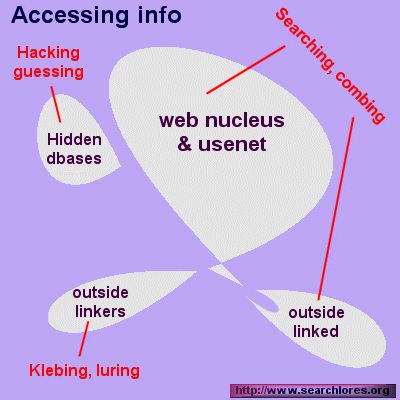
I hope you are not bored yet. The different "areas" we have examined above must be accessed using different techniques.
I will try to explain you some of them. This will concentrate on the fundamental issues, since I could else speak hours only to explain you the differences among the main search engines. If you are really interested, the links I offer will bring you far away inside our jungle.
In order to search effectively you must understand various techniques and apply them accordingly.
|