~ Malwares ~
| |
|
 |
|
malwares |
(Courtesy of fravia's advanced searching
lores)
(¯`·.¸ Delving deeper into Teleport Pro 1.29 ¸.·´¯)
by Noos
published at fravia's searchlores in
October 2000
Slightly edited by fravia+
See also Faulpelz's Teleport Pro 1.29, malware galore (May 2000) and
Faulpelz's Teleport Pro V1.29 (Build 1107) (January 2001)
which deals also with
this essay.
Interesting work: the "phone home"
part of the programs you insert into your own computers is most disturbing, and deserves to be
reversed black and blue by all 'freedom fighters'. A reason more to hate those political lackeyes of the
economical powers that be, that would like
to outlaw the use of disassemblers and debuggers in order not to disturb the wrongdoings
of their masters.
Interesting stab, feel free to build on this and contribute...
"Delving deeper into Teleport Pro 1.29"
by Noos
Foreword:
Ever since I downloaded version 1.0 of Teleport Pro it has been my
favourite program for retrieving
entire websites in a fast and easy way.
But as you can imagine after
reading Faulpelz's essay my curiosity
was triggered and I immediately downloaded version 1.29 of that
great product, anxious as to find out
what has hidden inside.
My findings:
Faulpelz was right on one part, teleport pro secretly connects to
www.tenmax.com, but not to request
a robots.txt file... nossir: to retrieve a update.txt. As most of you
might (and should) know, a robots.txt file is used
to store information for the search engine crawlers, and thus it
is perfectly normal for teleport pro
to check and retrieve that file for the host you are copying. I do
agree with Faulpelz that teleport pro
retrieves that file, but not on www.tenmax.com but simply on the
host you are copying. Faulpelz also mentioned
that the request for that file contained the URL of the site you
are copying, but this is simply necesarry
for name based virtual hosting.
But now for the thing that did not seem right. After installing
teleport pro 1.29 I set up the machines in
my LAN in the following way :
/ 10.0.0.7 (Web server I'm copying)
10.0.0.2 -----|
\ 10.0.0.3 (new IP of www.tenmax.com (HOSTS file) )
10.0.0.2 is the machine that is running teleport pro. In that
machines HOSTS file I added the
following line : 10.0.0.3 www.tenmax.com
The 10.0.0.3 machine also runs a web server so that requests to
www.tenmax.com won't bounce off.
Using that setup I created a new project and specified
http://10.0.0.7/ as the starting address.
At first I was a bit disappointed because it simply connected to
10.0.0.7, retrieved the files and disconnected.
Nothing suspicious at all. But I wasn't ready to give up at that
point since Faulpelz had seen something. After
numerous attempts teleport pro finally connected to 10.0.0.3 and
retrieved the earlier mentioned update.txt. Of course
this file did not exist on my web server, so I decided to go
online and manually retrieve the file from
www.tenmax.com.. but alas, the file did not exist there either. I
gave it one more shot using the exact
HTTP header teleport pro uses, but that also returned zilch.
This request could only mean 2 things in my opinion :
1. Log the IP's of all the users that use teleport pro. But this
does not make any sense since it only
connects every now and then.
2. Tenmax found out they were being naughty and removed the
update.txt which probably has been used
to tell teleport pro users that a new version is available. That
would also explain the necesity to
check every 50 projects or so (not sure WHEN it checks).
After finding out that it retrieves update.txt I disassembled
pro.exe to see what it does with that, but
I have not been able to find anything interesting about it.
0041A809 PHONE_HOME: ; CODE XREF:
sub_41A360+347j
0041A809 push ebx
0041A80A push 20h
0041A80C push ebx
0041A80D lea ecx, [ebp-40h]
0041A810 call sub_401E4D
0041A815 push offset aUpdate_txt ; "update.txt"
0041A81A push offset unk_47B10C ; path
0041A81F push offset aWww_tenmax_com ;"www.tenmax.com"
0041A824 push 50h
0041A826 push 1
0041A828 lea ecx, [ebp-80h]
0041A82B mov dword ptr [ebp-4], 0Ah
0041A832 call MakeAddress
0041A837 mov [ebp-1Ch], eax
0041A83A lea eax, [ebp-40h]
0041A83D mov edi, offset unk_47F040
What it does is create a URL from these 3 parts (host,path,file)
and place a request in it's queue.
But I have no idea when the results from that request are being
analyzed.
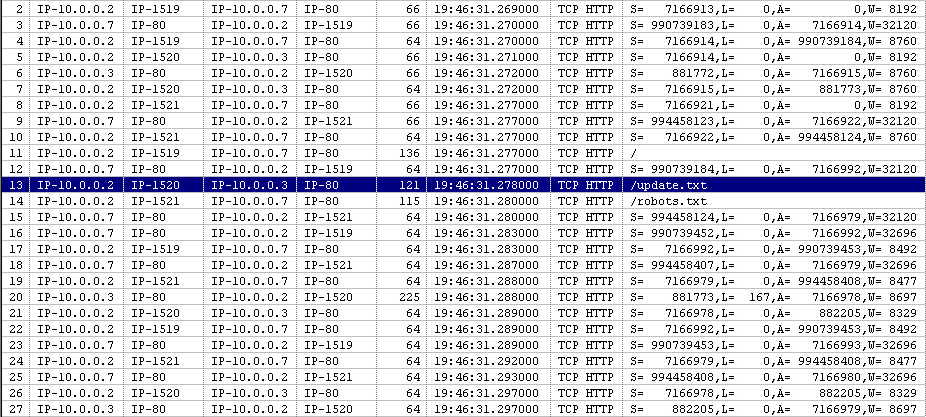
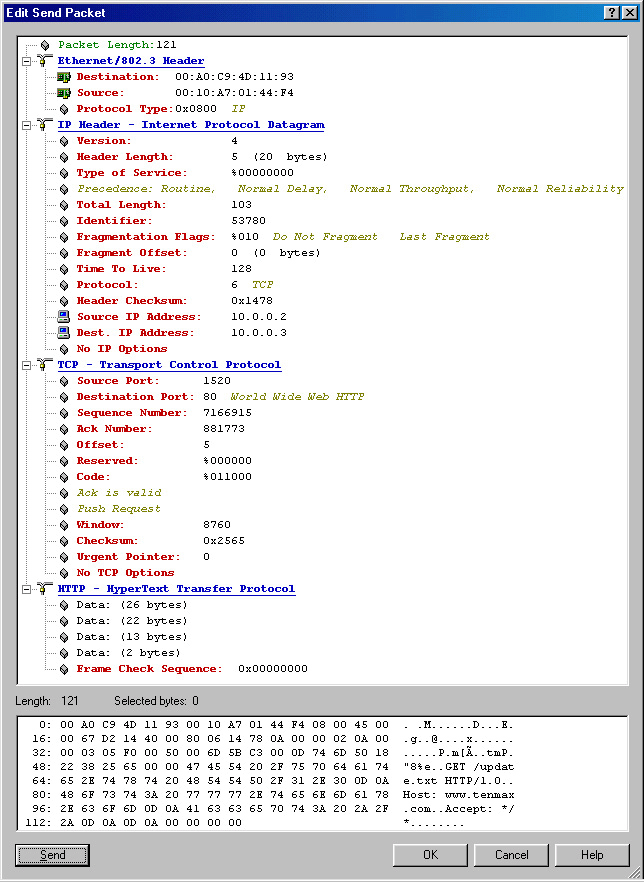
I have included to .gifs which display the results from my packet
sniffing. It clearly shows the request
being made to their server.
overview.gif
packet.gif
Afterword:
I doubt teleport pro has any more tricks up the sleeve. They
probably realized the update.txt wasn't such
a good idea. I also tried different settings with a proxy and
password protected sites, but no results until now...
- Noos, October 2000
(c) 2000: [fravia+], all rights
reserved
{kind=link}
{kind=link}